موتورهای جستجو چگونه کار می کنند؟
همانطور که در راهنمای سئو بتدی اشاره کردیم، موتورهای جستجو دستگاههای پاسخگو هستند. آنها برای کشف، درک و سازماندهی محتوای اینترنت به منظور ارائه نتایج مناسب به سؤالاتی که جستجوگرها از آنها درخواست می کنند، ایجاد شده اند.
برای نشان دادن نتایج جستجو، ابتدا باید محتوای شما برای موتورهای جستجو قابل مشاهده باشد. احتمالاً مهمترین قطعه معمای SEO است: اگر سایت شما یافت نشود، به هیچ وجه امکان حضور در SERPs (صفحه نتایج موتورهای جستجو) وجود ندارد.
موتورهای جستجو چگونه کار می کنند؟
موتورهای جستجو سه عملکرد اصلی دارند:
Crawl: هر جا که محتوا روی اینترنت باشد، می روند و لینک ها را بررسی می کنند.
Index: مطالب موجود در طی فرایند crawl را ذخیره و سازماندهی می کنند. هنگامی که یک صفحه ایندکس شود، شانس دارد که در نتایج جست و جو نشان داده شود.
Rank: براساس فاکتورهای بسیاری برای یک کوئری سرچ شده، سایت ها را رتبه بندی می کند.
Index: مطالب موجود در طی فرایند crawl را ذخیره و سازماندهی می کنند. هنگامی که یک صفحه ایندکس شود، شانس دارد که در نتایج جست و جو نشان داده شود.
Rank: براساس فاکتورهای بسیاری برای یک کوئری سرچ شده، سایت ها را رتبه بندی می کند.
عنکبوت یا خزنده های موتور جستجو چی هستند؟
خزیدن فرایند پیدا کردن است که طی آن موتورهای جستجو تیمی از ربات ها (معروف به خزنده یا عنکبوت) را برای یافتن مطالب جدید و به روز شده ارسال می کنند. محتوا می تواند متفاوت باشد – می تواند یک صفحه وب، یک تصویر، یک فیلم، یک PDF و … باشد. اما صرف نظر از قالب، محتوای توسط لینک ها (پیوند ها) کشف می شود.
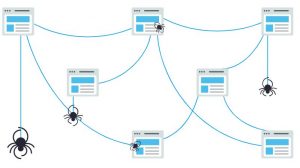
Googlebot با چند صفحه وب شروع به کار می کند، و سپس پیوندها را در این صفحه های وب دنبال می کند تا URL های جدید پیدا کند. با پیدا کردن میسرها روی یک صفحه، خزنده یا عنکبوت قادر است محتوای جدیدی پیدا کند و آن را به فهرست خود به نام Caffeine (پایگاه داده گسترده ای از URL های کشف شده) اضافه کند. بعداً وقتی جستجوگر در جستجوی اطلاعاتی باشد که محتوای مناسب و جواب آن سوال در آن URL باشد بازیابی می شود.
فهرست یا ایندکس موتور جستجو چیست؟
موتورهای جستجو اطلاعاتی را که در یک فهرست (همان ایندکس است) دارند پیدا می کنند، و پایگاه داده عظیمی از تمام مطالبی را که کشف کرده اند پردازش و ذخیره می کنند تا به اندازه کافی مناسب برای پاسخگویی به سوالات کاربران باشند.
آموزش سئو در مشهد با جواد یاسمی
رتبه بندی موتور جستجو
هنگامی که شخصی یک جستجو را انجام می دهد، موتورهای جستجو فهرست خود را برای آن سوال بررسی می کنند تا بهترین جواب ها را به ترتیب اهمیت و پاسخگو بودن لیست کنند. این ترتیب نتایج جستجو بر اساس اهمیت، به عنوان رتبه بندی شناخته می شود. به طور کلی، می توانید فرض کنید هرچه وب سایت رتبه بالاتری داشته باشد، موتور جستجو معتقد است که سایت پاسخ خوبی برای این پرس و جو یا کوئری باشد.
می توان خزنده های موتور جستجو را از بخشی یا تمام سایت شما مسدود کرد یا به موتورهای جستجو دستور داد که از ذخیره صفحات خاصی در فهرست آنها جلوگیری کنند. در حالی که می توانید دلایلی برای انجام این کار داشته باشد، اگر می خواهید محتوای شما توسط جستجوگرها پیدا شود، ابتدا باید اطمینان حاصل کنید که برای خزندگان و ربات های گوگل قابل دسترسی است و قابل ایندکس شدن است. در غیر این صورت، نامرئی هستند.
—————————————–
در سئو، همه موتورهای جستجو برابر نیستند
بسیاری از مبتدیان از اهمیت نسبی موتورهای جستجوگر خاص تعجب می کنند. بیشتر مردم می دانند که گوگل بیشترین سهم بازار را دارد، اما بهینه سازی بینگ، یاهو و دیگران چقدر مهم است؟ حقیقت این است که علیرغم وجود بیش از 30 موتور جستجوگر بزرگ وب، انجمن SEO تنها واقعاً به Google توجه می کند. چرا؟ پاسخ کوتاه این است که گوگل جایی است که اکثریت قریب به اتفاق افراد وب را جستجو می کنند. اگر از Google تصاویر، Google Maps و YouTube (یک ویژگی Google) استفاده کنیم، بیش از 90٪ جستجوهای وب در Google اتفاق می افتد – تقریباً 20 برابر Bing و Yahoo.
بسیاری از مبتدیان از اهمیت نسبی موتورهای جستجوگر خاص تعجب می کنند. بیشتر مردم می دانند که گوگل بیشترین سهم بازار را دارد، اما بهینه سازی بینگ، یاهو و دیگران چقدر مهم است؟ حقیقت این است که علیرغم وجود بیش از 30 موتور جستجوگر بزرگ وب، انجمن SEO تنها واقعاً به Google توجه می کند. چرا؟ پاسخ کوتاه این است که گوگل جایی است که اکثریت قریب به اتفاق افراد وب را جستجو می کنند. اگر از Google تصاویر، Google Maps و YouTube (یک ویژگی Google) استفاده کنیم، بیش از 90٪ جستجوهای وب در Google اتفاق می افتد – تقریباً 20 برابر Bing و Yahoo.
—————————————–
خزنده: آیا موتورهای جستجو می توانند صفحات شما را پیدا کنند؟
همانطور که تازه آموخته اید، اطمینان از اینکه سایت شما در دسترس خزنده ها و قابل ایندکس شدن باشد، پیش نیاز برای نمایش در SERP ها است. اگر یک وبمستر یا صاحب یک وب سایت هستید، شاید با دیدن تعداد بسیاری از صفحات شما در این فهرست شروع به کار کنید. این بینش بسیار خوبی در مورد اینکه آیا Google در حال خزیدن و یافتن تمام صفحاتی است که شما می خواهید رتبه بگیرند.
یکی از راه های بررسی صفحات فهرست بندی شده شما “site:yourdomain.com” ، یک اپراتور جستجوی پیشرفته است. به Google بروید و “site:alibaba.ir” را در نوار جستجو تایپ کنید. با این کار نتایج گوگل از صفحات سایت را که ایندکس شده اند را می بینید.
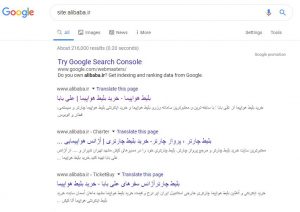
تعداد نتایج نمایش داده شده در گوگل دقیق نیست، اما این ایده را به شما می دهد که صفحات سایت شما ایندکس می شوند و الان چطوری در نتایج جستجو نشان می دهند.
برای نتایج دقیق تر، گزارش Index Coverage را در کنسول جستجوی Google بررسی کنید. اگر در حال حاضر آن را ندارید می توانید یک Google Search Console account بسازید. با استفاده از این ابزار، می توانید نقشه سایت برای سایت خود ست کنید و چک کنید که تعداد صفحات ارائه شده، به فهرست Google اضافه شده است یا خیر.
اگر در هیچ کجای نتایج جستجو نیستید، ممکن است به خاطر دلایل زیر باشد:
- سایت شما کاملاً جدید است و هنوز ربات گوگل آن را ندیده است.
- سایت شما با هیچ وب سایت دیگری لینک ندارد.
- منو، و لینک سازی داخلی سایت شما باعث می شود که یک ربات نتواد صفحات را به راحتی پیدا کند.
- سایت شما کدی دارد که موتورهای جستجو را مسدود کرده است.
- سایت شما توسط Google به دلیل تاکتیک های کلاه سیاه پنالتی و جریمه شده است.
به موتورهای جستجو بگویید چگونه سایت خود را خز کنند.
اگر از کنسول جستجوی Google یا اپراتور جستجوی پیشرفته “site: domain.com” استفاده کرده اید و متوجه شده اید که برخی از صفحات مهم شما از ایندکس حذف نشده اند و یا برخی از صفحات بی اهمیت شما به طور اشتباه به ایندکس شده اند، نکاتی برای بهینه سازی این وضعیت وجود دارد. با اجرایی کردن آن های به Googlebot کمک می کنید که بهتر محتوای وبسایت شما را کرال کند. راستی کرال باجت، مشکلات کرال شدن صفحات جدید و اینکه بررسی آپدیت های شما توسط ربات های گوگل را جدی بگیرید.
اکثر مردم فکر می کنند که Google می تواند صفحات مهم را خودش پیدا کند. این موارد ممکن است شامل مواردی مانند URL های قدیمی باشد که دارای محتوای کم، لینک های تکراری (مانند پارامترهای مرتب سازی و فیلتر برای تجارت الکترونیکی)، صفحات تبلیغی ویژه، صفحات مرحله بندی یا تست و … هستند.
برای دسترسی و یا عدم دسترسی Googlebot به صفحات و بخشهای خاص سایت خود، از robots.txt استفاده کنید.
Robots.txt
فایل های Robots.txt در فهرست اصلی وب سایت ها قرار دارند (مانند yourdomain.com/robots.txt) و نشان می دهد کدام قسمت از موتورهای جستجوگر سایت شما باید و نباید کرال شوند، همچنین سرعتی که سایت شما را کرال می کند.
چگونه Googlebot با پرونده robots.txt رفتار می کند.
- اگر Googlebot نتواند یک فایل robots.txt برای یک سایت پیدا کند، خودش می رود برای کرال کردن سایت.
- اگر Googlebot یک فایل robots.txt را برای یک سایت پیدا کند، معمولاً پیشنهادات را قبول می کند.
- اگر Googlebot هنگام تلاش برای دسترسی به فایل robots.txt یک سایت با خطایی روبرو شود و نتواند تعیین کند که این فایل وجود دارد یا خیر، نمی تواند سایت را کرال کند.
بودجه کرال سایت را بهینه سازی کنید!
بودجه کرال میانگین تعداد URL هایی است که Googlebot قبل از خروج از سایت شما کرال کرده است، بنابراین بهینه سازی بودجه خزیدن یعنی اطمینان حاصل کنید که Googlebot وقت زیادی را برای خزیدن از طریق صفحات بی اهمیت خود تلف نمی کند، و خطر دیده نشدن و کرال نشدن صفحات مهم شما است. بودجه کرال در سایتهای بسیار بزرگ با ده ها هزار آدرس اینترنتی مهم است، اما اصلا بد نیست که دسترسی خزندگان به محتوا را که به آنها اهمیت نمی دهید مسدود کنید. فقط اطمینان حاصل کنید که دسترسی یک خزنده به صفحاتی که در آن ها کلی لینک و دسترسی به صفحات دیگر است مسدود نکنید. اگر دسترسی Googlebot به یک صفحه مسدود شده باشد، بعد از آن صفحه را کرال نمی کند.
همه ربات های وب از robots.txt پیروی نمی کنند. افراد با نیت بد (به عنوان مثال، اسکرپرها آدرس ایمیل) ربات هایی را ایجاد می کنند که از این پروتکل پیروی نمی کنند. در حقیقت، برخی بازیگران بد از پرونده های robots.txt استفاده می کنند تا بفهمند محتوای خصوصی خود را در کجا قرار داده اید. اگرچه به نظر می رسد مسدود کردن خزنده ها از صفحات خصوصی مانند ورود به سایت و صفحه های مدیریت منطقی به نظر برسد، زیرا در این فهرست قرار نمی گیرند، قرار دادن محل آن URL ها در یک فایل قابل دسترسی عمومی robots.txt همچنین به معنای این است که افراد با قصد مخرب راحت تر می توانید آنها را پیدا کنند، بهتر است این صفحات را NoIndex کنید.
تعریف پارامترهای URL در GSC
برخی از سایت ها (رایج ترین ها تجارت الکترونیکی ها هستند) با اضافه کردن پارامترهای خاصی در URL ها، محتوای مشابه را در چندین URL مختلف در دسترس قرار می دهند. اگر به صورت آنلاین خرید کرده باشید متوجه شدید در یک وبسایت باید محصولی که سرچ کرده اید را دقیق تر و دقیق تر کنید، احتمالاً جستجوی خود را از طریق فیلترها کاهش داده اید. به عنوان مثال، شما می توانید “کفش” را در آمازون جستجو کنید، و سپس جستجوی خود را با توجه به اندازه، رنگ و سبک اصلاح کنید. هر بار که پالایش می کنید، URL کمی تغییر می کند:
https://www.example.com/products/women/dresses/green.htmhttps://www.example.com/products/women?category=dresses&color=greenhttps://example.com/shopindex.php?product_id=32&highlight=green+dress&cat_id=1&sessionid=123$affid=43
چگونه گوگل می داند کدام نسخه از URL را برای کاربرانش ارائه کند؟ گوگل به خوبی می داند URL اصلی را به تنهایی تشخیص دهد، اما می توانید از فیچرهای پارامترهای URL در کنسول جستجوی Google استفاده کنید تا دقیقاً به Google بگویید که چگونه می خواهید آنها را با صفحات خود متمایز کنید. اگر از این ویژگی برای گفتن Googlebot به “کرال این URL بدون پارامتر ____ ” استفاده می کنید، در اصل می خواهید این محتوا را از Googlebot مخفی کنید، که می تواند منجر به حذف آن صفحات از نتایج جستجو شود. اگر این پارامترها صفحات تکراری ایجاد کنند، همان چیزی است که شما می خواهید، اما اگر می خواهید این صفحات ایندکس شوند، اصلا مناسب نیستند.
آیا ربات های خزنده می توانند محتوای مهم شما را پیدا کنند؟
الان که نکاتی در مورد اینکه چطوری جلوی ربات های گوگل برای کرال نکردن صفحات بی ارزش را می دانید، بیایید در مورد بهینه سازی هایی که می تواند به Googlebot کمک کند تا صفحات مهم شما را پیدا کند، بپردازیم.
بعضی مواقع موتور جستجو می تواند با خزیدن قسمت هایی از سایت شما را پیدا کند، اما صفحات یا بخش های دیگر ممکن است به دلایلی از دید ربات پنهان بمانند. این مهم است که مطمئن شوید موتورهای جستجو قادر به پیدا کردن تمام مطالب مورد نظر و مهم شما هستند و نه فقط صفحه اصلی شما.
از خود این سوال را بپرسید: آیا ربات می تواند بین صفحات شما بخزد و همه ی آنها را مشاهده کند؟
نظرات
ارسال یک نظر